Feature Store Overview
The JFrog ML Feature Store is a centralized service for developing, sharing, and serving machine learning features with consistency across training and inference.
A feature store is a centralized repository that manages the lifecycle of machine learning features, from ingestion and transformation to storage and serving. It addresses a common challenge in machine learning workflows: keeping the features used during model training consistent with those used during inference.
The JFrog ML Feature Store lets you define features once and reuse them across projects and teams. You can develop features from batch or streaming data sources, serve them for real-time inference, and retrieve them as point-in-time training datasets, all from a single, shared location.
The Feature Store provides the following key benefits:
- Single source of truth: All features are stored in one discoverable location, so your models always reference the same data.
- Cross-team collaboration: Data scientists and machine learning engineers can share and reuse features across projects instead of recreating them.
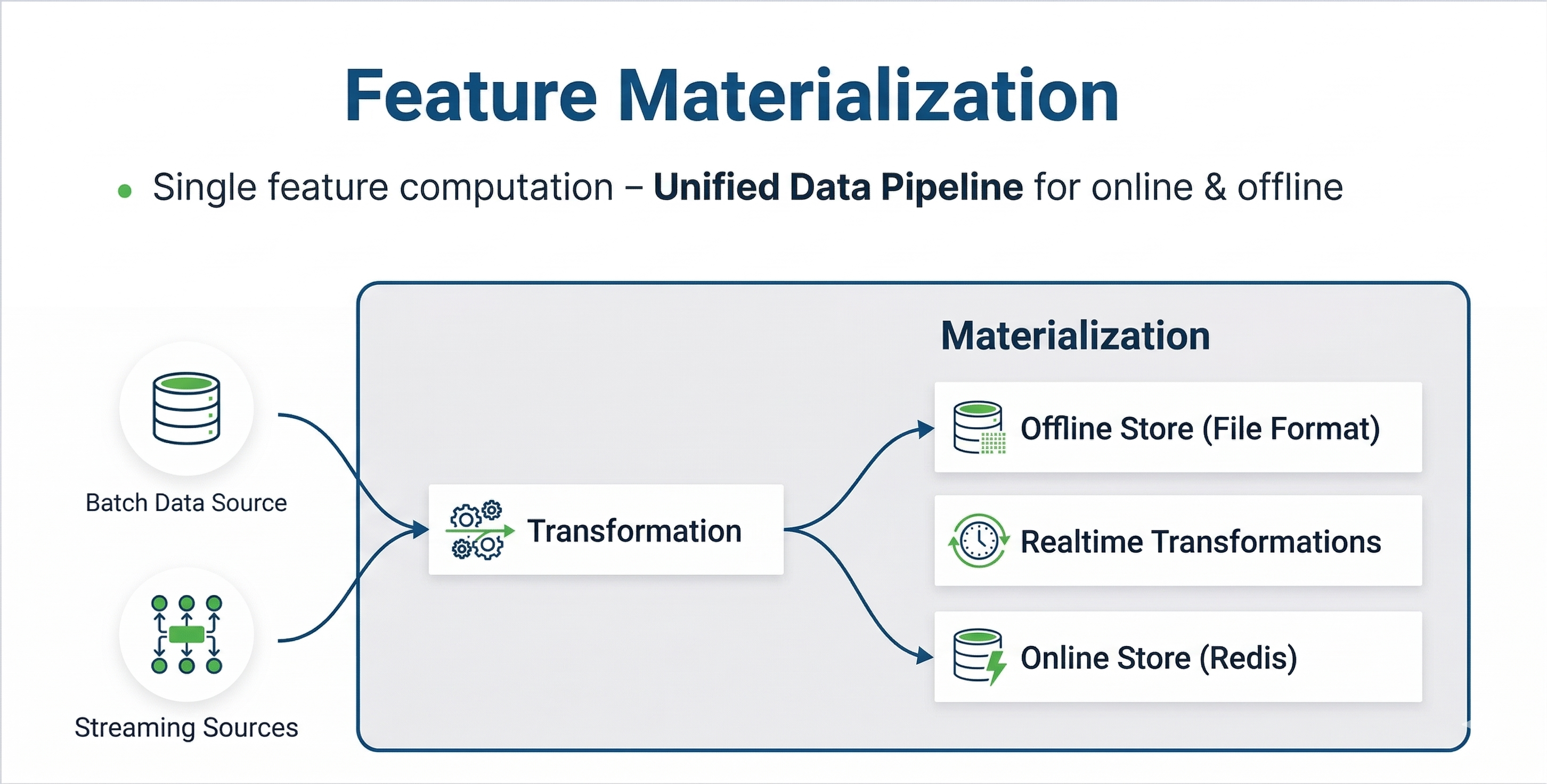
- Training and serving consistency: Features generated for training (offline) and inference (online) come from the same extraction process, preventing training-serving skew.
Feature Store Concepts
The JFrog ML Feature Store is built on three core concepts:
| Concept | Description |
|---|---|
| Entity Keys | The identifiers (for example, user_id, transaction_id, merchant_id) for which feature values are calculated and retrieved. |
| Data Sources | The external systems (for example, databases, event streams) from which raw data is ingested to create features. For more information, see Data Sources. |
| Feature Sets | The operational unit of the Feature Store. A feature set is a computational definition (schema and logic) that takes raw data as input and outputs a logical group of related features. For more information, see Feature Sets. |
Feature sets come in three types:
- Batch feature sets: Features defined from static or historical data sources such as Snowflake or BigQuery.
- Streaming feature sets: Features defined from streaming data sources such as Kafka for continuous, near real-time updates.
- Real-time feature sets: Features computed from data provided directly at inference time, rather than pre-computed.
Note:
JFrog ML SaaS supports batch feature sets only. To use real-time and streaming feature sets, use a JFrog ML hybrid deployment.
Feature Consumption
With the JFrog ML Feature Store you can define features once, calculate them once, and reuse them at any time.
The Feature Store populates both the offline and online stores from the same feature extraction process, ensuring consistency between training and inference data.
- Inference: Serve the most up-to-date feature values for a given entity key from a centralized online store.
- Training: Retrieve historical feature values at any point in time from the offline store for model training.
Updated 4 months ago